Математический анализ в Maple 9
Процедуры пакета CurveFitting
В Maple есть пакет, который предназначен специально для выполнения различного рода аппроксимаций. Речь идет о пакете CurveFitting. Ниже
описываются основные функции и процедуры, которые будут доступны после подключения данного пакета.
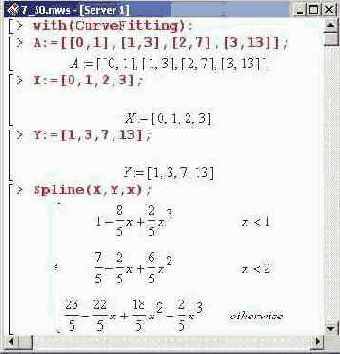
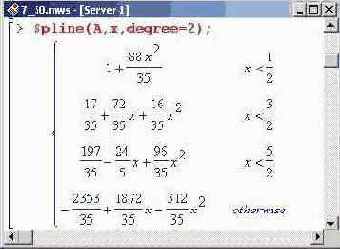
Для выполнения сплайн-интерполяции в пакете CurveFitting предлагается процедура Spline (), действие которой практически полностью аналогично встроенной процедуре spline(), однако по сравнению с последней данная процедура имеет более свободный синтаксис вызова. Причем один из способов указания аргументов такой же, как и у процедуры splinef). Исключение составляет четвертый необязательный параметр. В данном случае степень базового полинома указывается так: значение, где в качестве значение следует ввести целое положительное число (по умолчанию принимается равным 3). Еще один способ вызова подразумевает указание вместо первых двух параметров (списка узловых точек и списка значений функции в этих точках) одного списка с элементами "точка-значение". Другими словами, аргументом процедуры можно использовать список из списков, как это было в разработанной ранее процедуре lagr(). Правда, та процедура действовала на интерполяционную переменную, являясь функциональным оператором. В этом случае интерполяционная переменная указывается в качестве аргумента процедуры. На этом, пожалуй, особенности процедуры Spline() исчерпываются. Ниже приведены примеры ее использования.
На заметку
В Maple 9 в процедуре Spline() допускается использование опции endpoints, значениями которой могут быть ключевые слова natural (значение по умолчанию), notaknot или periodic. С помощью этой опции задается тип условий на границах интервала интерполирования. В качестве значения может также указываться список, массив или матрица, определяющие характер поведения функции или ее производных на границах интервала.
Практически те же замечания можно отнести и к процедуре интерполирования полиномами Polynomiallnterpolation(), предлагаемой в пакете CurveFit-ting. От встроенной процедуры interp() эта отличается возможностью использования в качестве аргументов либо двух списков, либо одного — в полной аналогии с процедурой Spline (). Вот пример ее вызова.
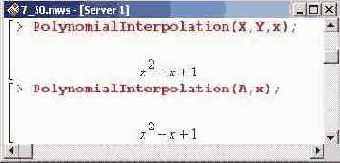
Как видим, результат один и тот же.
На заметку
В Maple 9 процедура Polynomial interpolation () имеет опцию form, которая определяет, в каком виде будет выведен на экран интерполяционный полином. Ее возможными значениями являются ключевые слова Lagrange, monomial, Newton и power.
Однако возможности пакета этим не исчерпываются. Рассмотрим процедуру Rationallnterpolation(), которая позволяет находить интерполяционную-функцию в виде рациональной дроби, где числитель и знаменатель являются полиномами. Порядок вызова процедуры следующий. Сначала указывается список узлов и список значений функции в этих узлах. В качестве альтернативы может быть задан также один список с парами "точка—значение". Далее указывается интерполяционная переменная. На этом обязательные параметры заканчиваются. В качестве необязательных параметров могут указываться значения для опций method и degree (значения указываются так: опция, знак равенства, значение опции). Для опции method, определяющей метод обработки сингулярностей, возможны два значения: lookaround (метод "обхода" сингулярностей, используется по умолчанию) и subresultant (метод "перехода" через сингулярности). Для опции degree значение указывается в виде списка, элементы которого задают степени полиномов числителя и знаменателя соответственно. Вот как данная процедура выглядит в действии.

Чтобы сравнить разные способы интерполирования, построим графики соответствующих интерполяционных функций.
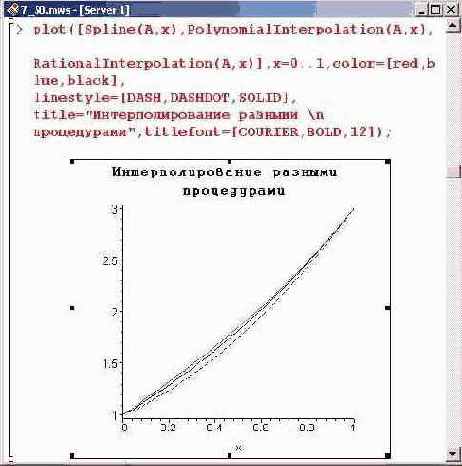
Интервал для отображения графиков не случайно указан до 1, а не до 3, как можно было бы предположить. Дело в том, что в последнем случае разницу между интерполяционными функциями заметить вообще невозможно. Отсюда напрашивается вывод, что выбор той или иной процедуры для построения интерполяционной функции — вопрос сугубо индивидуальный и заранее, до постановки задачи, решен быть не может.
Наконец, процедура LeastSquares() из пакета CurveFitting, которую здесь рассмотрим, позволяет аппроксимировать табулированную функцию, используя метод наименьших квадратов. Метод используется, как правило, в тех случаях, когда число подгоночных параметров (тех параметров, которые могут выбираться пользователем) существенно меньше числа базовых табличных точек. Идея метода состоит в том, чтобы найти такие значения для параметров аппроксимирующей функции, что ее отклонение от табличных значений в узловых точках было бы минимальным. Для этого вводят функцию где {а} — набор параметров аппроксимирую-щей функции — узловые точки и значения аппроксимируемой функции в этих точках соответственно; а <», — весовые множители, которые обычно выбираются равными единице. Задача состоит в том, чтобы за счет параметров {а,} минимизировать записанную выше функцию Ща,}). Общий метод решения заключается в нахождении частных производных от этой функции по каждому из параметров, после чего полученные выражения прирйвииваются к нулю, такая система решается и полученные в качестве ее решения точки исследуются на экстремум.
Внимание!
Если аппроксимирующая функция получена по методу наименьших квадратов, то никакой гарантии в том, что она проходит не то что через все, а хотя бы через одну базовую табличную точку, нет. В этом смысле метод наименьших квадратов принципиально отличается от рассмотренных ранее способов построения интерполяционной функции. Именно поэтому функцию, получаемую при использовании метода наименьших квадратов, будем называть не интерполирующей, аппроксимирующей.
Использование процедуры LeastSquares () позволяет сразу получить желаемый результат. Для этого следует ввести соответствующую команду, указав ее параметрами либо два списка с узлами и значениями функции, либо один с элементами-списками, в которых первый элемент является узловой точкой, а второй — значением функции в этой точке. После этого указывается название переменной. Если на этом остановиться, то после выполнения процедуры результат будет возвращен в виде линейной зависимости по аргументу. Ниже в табл. 7.2 представлено детальное описание опций, которые, помимо обязательных аргументов, могут использоваться вместе с процедурой LeastSquares().
Таблица 7.2. Опции процедуры LeastSquares ()
| Опция | Описание |
| curve | Определяет общий вид аппроксимирующей кривой. Зависимость должна быть линейной по параметрам! На зависимость функции от аргумента ограничения не накладываются |
| parame | Может использоваться в тех случаях, когда явно задана опция curve. Значение данной опции задается в виде списка переменных, которые следует считать параметрами оптимизации. Если значение не задано, параметрами оптимизации считаются все переменные, отличные от той, что указана в параметрах процедуры как независимая |
| weight | Определяет весовые множители. Ее значением может быть список из неотрицательных чисел, а число элементов списка должно строго соответствовать числу узловых точек |
Для того чтобы продемонстрировать работу процедуры LeastSquares (), поступим следующим образом. Сначала зададим базовую функцию, которую затем будем восстанавливать по табличным данным. Функцию эту возьмем в следующем виде.

Чтобы задача не была слишком простой, внесем некий элемент случайности. Для этого воспользуемся генератором случайных чисел. Табулируем значения функции так: после вычисления значения функции в узле согласно приведенной выше формуле, к этому значению будем добавлять случайное число в диапазоне от 0 до 1. Таким образом, табличные значения функции будут иметь погрешность примерно 10 процентов. Ниже показана группа команд, в которой инициализируется генератор случайных чисел (численный параметр указан для того, чтобы при каждом новом запуске генерировалась одна и та же последовательность чисел) и определяется процедура RV(), генерирующая случайное число в диапазоне от 0 до 100. Затем переменная В заполняется парами значений узлов и функции (с учетом погрешности), и конечное ее значение отображается в области вывода. При заполнении списка В значения функции преобразуются в формат чисел с плавающей точкой. Кроме того, поскольку процедура RV() генерирует случайное число в диапазоне от 1 до 100 (а нужно, чтобы оно было в диапазоне от 0 до 1), это число делится на 100.
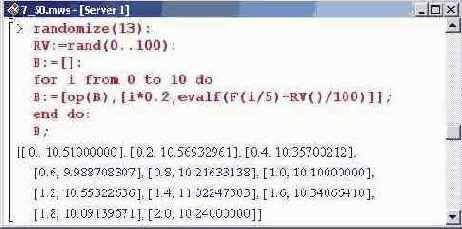
Теперь по базовым точкам выполним аппроксимацию. Сначала воспользуемся линейной зависимостью, предлагаемой по умолчанию.
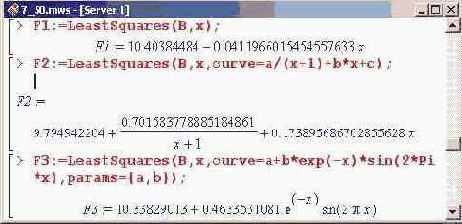
В пределах погрешности, с которой определялись базовые точки, параметры определены совсем не плохо.
Внимание!
Выше при вызове процедуры LeastSquares() обязательно следует указывать значение для опции params. Если этого не сделать, то константа Pi в аргументе синуса будет интерпретироваться как параметр оптимизации. Поскольку функция по параметру нелинейна, ничем хорошим это не закончится (появится сообщение об ошибке).
Построим графики для полученных зависимостей. Вместе с графиками квадратами отобразим точки, по которым выполнялась оптимизация.
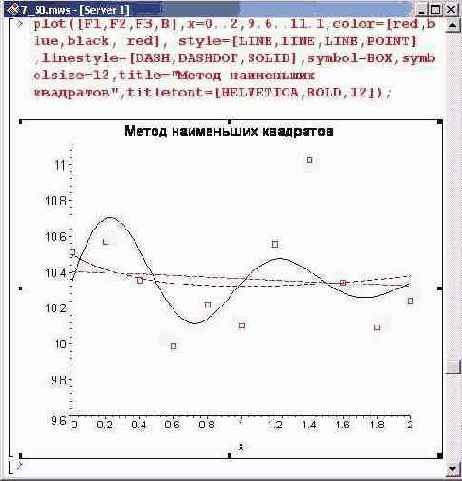
Первые две штрихованные кривые мало чем отличаются, в то время как третья (сплошная линия) достаточно точно отображает исходную зависимость. Однако чтобы в общем случае методом наименьших квадратов эффективно строить аппроксимирующие функции, необходимо знать вид аппроксимируемой функциональной зависимости.